This is the first part of “An Outsider’s Tour of Reinforcement Learning.” Part 2 is here.
If you read hacker news, you’d think that deep reinforcement learning can be used to solve any problem. Deep RL has claimed to achieve superhuman performance on Go, beat atari games, control complex robotic systems, automatically tune deep learning systems, manage queueing in network stacks, and improve energy efficiency in data centers. What a miraculous technology! I personally get suspicious when audacious claims like this are thrown about in press releases, and I get even more suspicious when other researchers call into question their reproducibility. I want to take a few posts to unpack what is legitimately interesting and promising in RL and what is probably just hype. I also want to take this opportunity to argue in favor of more of us working on RL: some of the most important and pressing problems in machine learning are going to require solving exactly the problems RL sets out to solve.
Reinforcement learning trips people up because it requires thinking about core concepts that are not commonly discussed in a first course on machine learning. First, you have to think about statistical models that evolve over time, and understand the nature of dependencies in data that is temporally correlated. Second, you need to understand feedback in statistical learning problems, and this makes all of the analysis challenging. When there is feedback, the distribution of the observations changes with every action taken, and an RL system must adapt to these actions. Both of these are complex challenges, and I’m going to spend time discussing both. Indeed, I can use both of these concepts to introduce RL from seemingly unrelated starting points. In this post, I’ll dive into RL as a form of predictive analytics. In the next post, I’ll describe RL as a form of optimal control. Both derivations will highlight how RL is different from the machine learning with which we are most familiar.
Reinforcement Learning As Predictive Analytics
Chris Wiggins introduced a brilliant taxonomy of ML that I find rather clarifying.
There are three main pillars of machine learning: unsupervised, supervised, and reinforcement learning. There are few other kinds of machine learning that are connected to one of these three core categories—notably semi-supervised learning and active learning—but I think this trichotomy nicely covers most of the current research in machine learning.
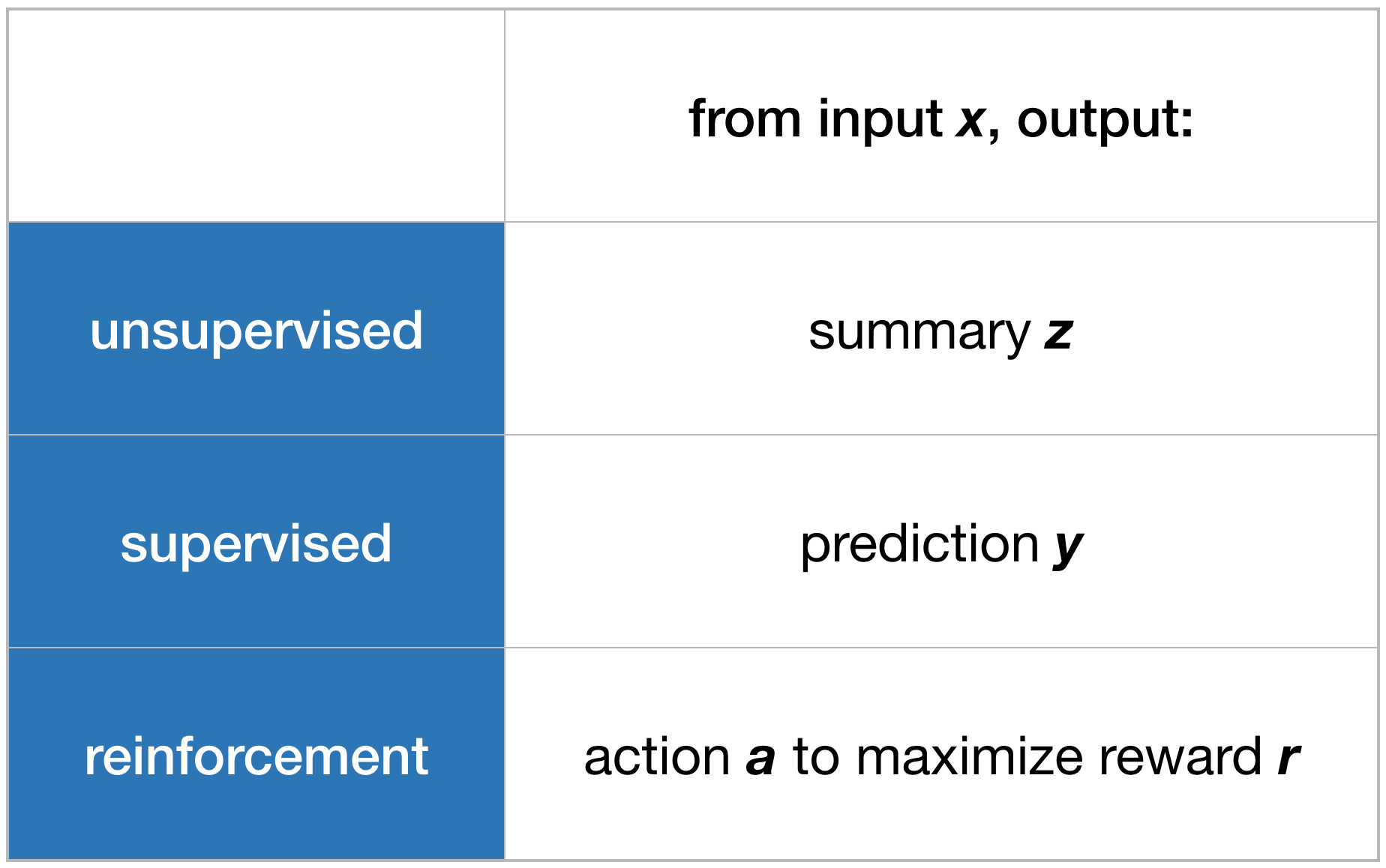
What is the difference between each of these? In all three cases, you are given access to some table of data where the rows index examples and the columns index features (or attributes) of the data.
In unsupervised learning, the goal is to summarize the examples. We can say that each row has a list of attributes x, and the goal is to create a shorter list of attributes z for each example that somehow summarizes the salient information in x. The features in z could be assignment to clusters or some sort of mapping of the example into a two dimensional state for plotting.


In supervised learning, one of the columns is special. This is the feature which we’d like to predict from the other features. The goal is to predict y from x such that on new data you are accurately predicting y. This is the form of machine learning we’re most familiar with and includes classification and regression as special cases.
In reinforcement learning, there are two special columns, a and r. The goal is to analyze x and then subsequently choose a so that r is large. There are an endless number of problems where this formulation is applied from online decision making in games to immoral engagement maximization on the web.
The broader field of data science has terminology for all of these analytical procedures as well. Indeed, much of ML fits cleanly inside bins of data analytics, laid out in terms of difficulty and value in this chart which I have adapted from a famous infographic of Gartner:
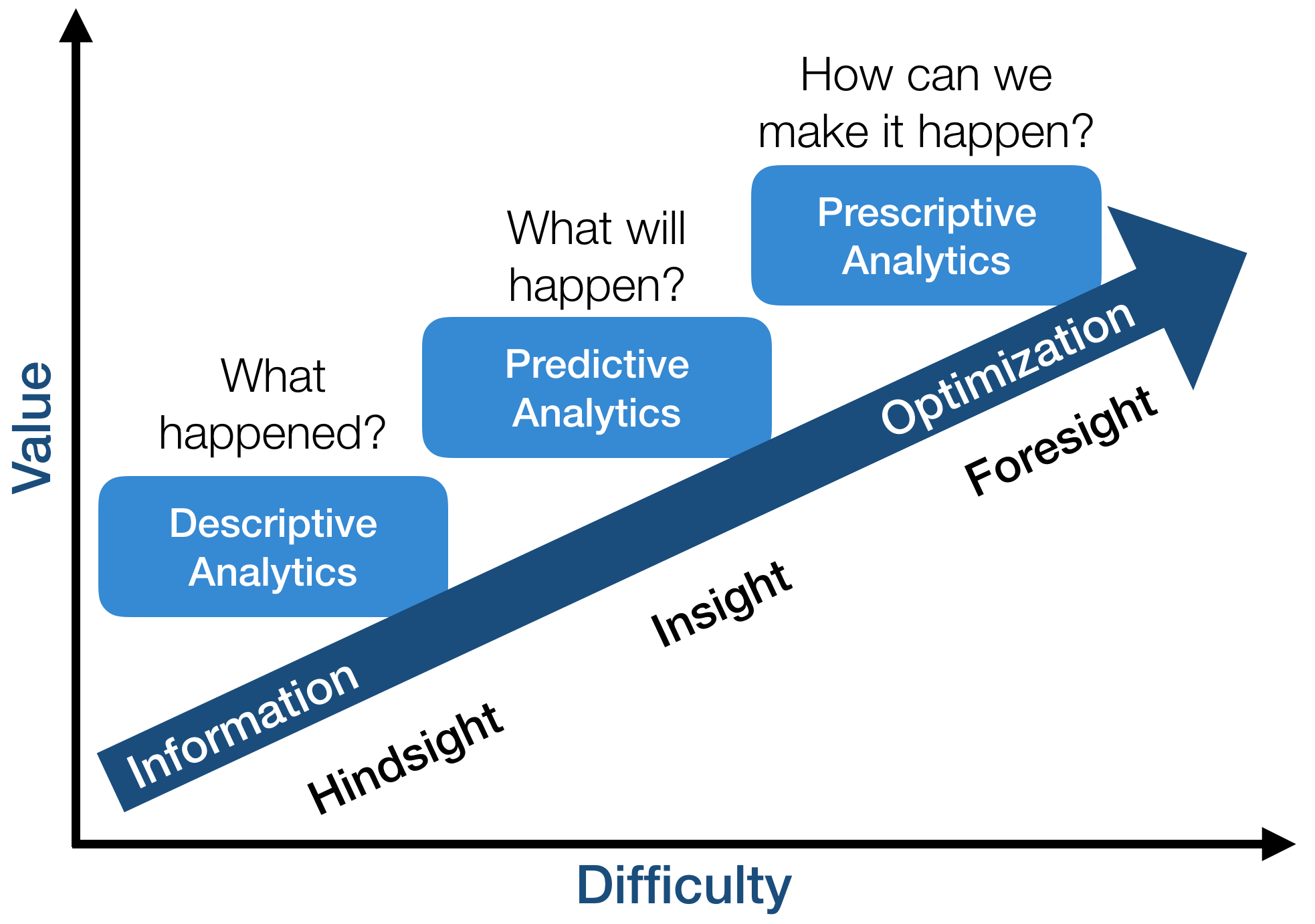
Descriptive analytics refers to summarizing data in a way to make it more interpretable. Unsupervised learning is a form of descriptive analytics. Predictive analytics aims to estimate outcomes from current data. Supervised learning is a kind of predictive analytics. Finally, prescriptive analytics guides actions to take in order to guarantee outcomes. RL as described here falls into this bucket.
Note that the value assessments in this chart seems to fly in the face of conventional wisdom in machine learning (e.g., 1, 2, 3, 4 ). But the conventional wisdom is wrong, and it’s important that we correct it. According to Gartner, business leaders, and your humble blogger, unsupervised learning is by far the easiest of the three types of machine learning problems because the stakes are so low. If all you need to do is summarize, there is no wrong answer. Whether or not your bedrooms are rendered correctly by a GAN has no impact on anything. Descriptive analytics and unsupervised learning lean more on aesthetics and less on concrete targets. Predictive analysis and supervised learning are more challenging as we can evaluate accuracy in a principled manner on new data.
The most challenging form of analytics and the one that can return the most value is prescriptive analytics. The value proposition is clear: prescriptive analysis and reinforcement learning demand interventions with the promise that these actions will directly lead to valuable returns. Prescriptive analysis consumes new data about and uncertain and evolving environment, makes predictions, and uses these predictions to impact the world. Such systems promise plentiful rewards for good decisions, but the complicated feedback arising from the interconnection is hard to study in theory, and failures can lead to catastrophic consequences. In real computing systems, whether they be autonomous transportation system or seemingly mundane social engagement systems like Facebook, actively interacting with reality has considerably higher stakes than scatter plotting a static data set for a PowerPoint presentation.
Indeed, this is why I’ve been so obsessed with understanding RL for the past few years. RL provides a useful framework to conceptualize interaction in machine learning. As I’ve been hammering on for a while now, we have to take responsibility for our machine learning systems and understand what happens when we set them loose on the world. The stakes couldn’t be higher, and I think that understanding a bit more about RL can help us build safer machine learning systems in general. For these reasons, I do hope you’ll humor me in sticking it out for my outsider’s tour of the area. You can start with Part 2, where I describe reinforcement learning from the perspective of optimal control.